I have been assisting a faculty member within the Marketing Department with an ongoing research project involving U.S. senatorial elections over the past 36 years. For each election a set of media articles were gathered along with some meta data (title, publication, etc.) making up a corpus. Each corpus contains, on average, 3,000 articles. The researcher wanted to group similar articles by topics, and suggested applying Latent Dirichlet allocation(LDA) to each corpus. The computing power needed to run this set of tasks was huge, so I recruited the help of the Wharton High-Performance Computing team and the use of the High Performance Computing Cluster (HPCC).
LDA
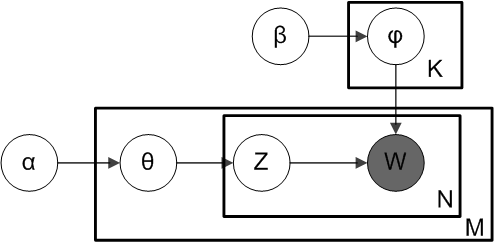
If you are not familiar with LDA, here are some highlights from Wikipedia:
In natural language processing, Latent Dirichlet allocation (LDA) is a generative model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. For example, if observations are words collected into documents, it posits that each document is a mixture of a small number of topics and that each word’s creation is attributable to one of the document’s topics.
I’m not sure about you, but after reading that I was still a little confused. If you want a better laymen explanation, check out this blog post – or just consider these three basic rules of thumb regarding LDA before reading on:
- Each article may be viewed as a mixture of various topics. An article will be assigned a probability (0.0 through 1.0) that it belongs to a single topic. The sum of the probabilities for all topics for a single article will be 1.0.
- The LDA algorithm must be supplied with the number of topics to classify each article across.
- Each topic can be defined by a list of topic words from which the researcher should be able to interpret and label appropriately; for example, in a topic word list of “strike, out, bat, ball, walk, run, home run,” we can, with a high level of certainty, label the topic “baseball.”
About the Corpora
There were 564 senatorial elections between 1980 and 2012 (or at least that was the number the researcher was interested in, anyway). The researcher supplied me with a set of articles for each election, which I compiled into a CSV file for each election. These files were the input for the LDA analysis.
The researcher faced a difficult challenge in deciding the number of topics, so she decided to run LDA on each election corpus three times, each time with a different number of topics determined by the total number of articles in the corpus. That way she could choose among the three output files that offered the best level of interpretability. She decided on the following formulas to determine the topic count:
- Min(ceiling(Number of Articles * 0.1), 50)
- Max(2, ceiling(Sqrt(Number of Articles) /2))
- Max(2, ceiling(Sqrt(Number of Articles)))
Why Python?
Python made sense for this project because it has a mature LDA package and a well-earned reputation for offering great tools and packages in the natural language-processing area. I have previously worked with NLTK and knew it would be an invaluable tool for this project.
I closely followed a blog post on chris’ sandbox as well as this Gist article, which helpfully provide more in-depth details on the actual LDA implementation. The finished script ended up with just over 100 lines of code and took one argument (the CSV file mentioned above).
Running the Jobs on the HPCC
LDA modeling is very memory intensive and the iterative nature of the process puts a lot of demand on the CPU – i.e., this job was too big to run on my laptop. So I reached out to the Wharton High-Performance Computing team to discuss the best way to run this on their HPCC. First, I had to setup my python environment and install the necessary packages. Then I needed a way to loop through all the input files and submit the job to the cluster. This seemed like a perfect match for an Array Job. With the following bash script all of my 564 jobs were submitted to the cluster:
# !/bin/bash #$ -N lda #$ -t 1-564 #$ -l m_mem_free=16G #$ -j y source ~/lda/bin/activate INCSV="`find input -iname '*per_article_totals.csv*' |head -n$SGE_TASK_ID |tail -n1`" echo "TASK $SGE_TASK_ID $INCSV" python main.py "$INCSV" #this file is named lda.sh
#$ -N lda sets the name of the job to lda
#$ -t 1-564 sets the index to range from 1 inclusive to 564
#$ -l m_mem_free=16G allocates 16gb of ram for each job.
#$ -j y joins the stdout and stderr log files.
source ~/lda/bin/activate activates my virtual python env.
INCSV=”`find input -iname ‘*per_article_totals.csv*’ |head -n$SGE_TASK_ID |tail -n1`”
In this command, $SGE_TASK_ID refers to the index ranging from 1-564. Let’s call it n. So, the temporary variable INCSV is set to the result of the find command stripped to the length nth result. This result is then piped to a tail, removing all but the last element, leaving just the nth file. This solution is particular to the layout and file-naming convention of my input files, but you can see that, as the index grows, a new file will be saved to the INCSV variable.
echo “TASK $SGE_TASK_ID $INCSV” Echo the input file name for logging purposes.
python main.py “$INCSV” Start the python job with its first and only argument as the input file.
I then submit this job to the cluster with the qsub lda.sh command. The 564 tasks were subsequently run across 92 nodes, and the entire job was completed within 4 hours.
Some Interesting Results
Rick Santorum vs. Bob Casey, Jr. 2006
You may remember the controversy caused over former Sen. Rick Santorum’s residency:
While Santorum maintained a small residence in Penn Hills, a township near Pittsburgh, his family primarily lived in a large house in Leesburg, a suburb of Washington, D.C. in Northern Virginia…Santorum also drew criticism for enrolling five of his six children in an online “cyber school” in Pennsylvania’s Allegheny County (home to Pittsburgh and most of its suburbs), despite the fact that the children lived in Virginia. The Penn Hills School District was billed $73,000 in tuition for the cyber classes.[26]
Keep in mind that in the output of an LDA, each topic is defined by a list of topic words. Thus, we should not be surprised if one of the Santorum/Casey topics is made up of the following top 30 words:
- santorum school children home family penn hills church man sen police rick pennsylvania state senator people right one district house live wife women washington virginia two us pay law kids
2008 Senatorial Elections
A random sampling of the 2008 election features topic words such as:
- obama said mccain virginia campaign presidential kaine sen warner democratic barack state gov webb john running president former candidate vice republican would palin national nominee mate senator m mark governor
- mccain obama bush republican would president campaign presidential party senator democrats john said republicans barack house voters one democratic election washington candidate white political new clinton change going country week
- obama mccain palin m election campaign p barack presidential john voters vote state sarah florida states news america republican candidate win polls night votes biden voting even victory says ohio
Each of these lists were pulled from separate elections – all from 2008. But since this was a presidential election year, there is also a topic for articles that specifically deal with candidates John McCain and Barack Obama.
Conclusion
As you can see, there is a lot of power in the LDA algorithm – and power to spare on Wharton’s HPCC.
(For additional technical details, feel free to reach out to me directly for with any specific questions!)