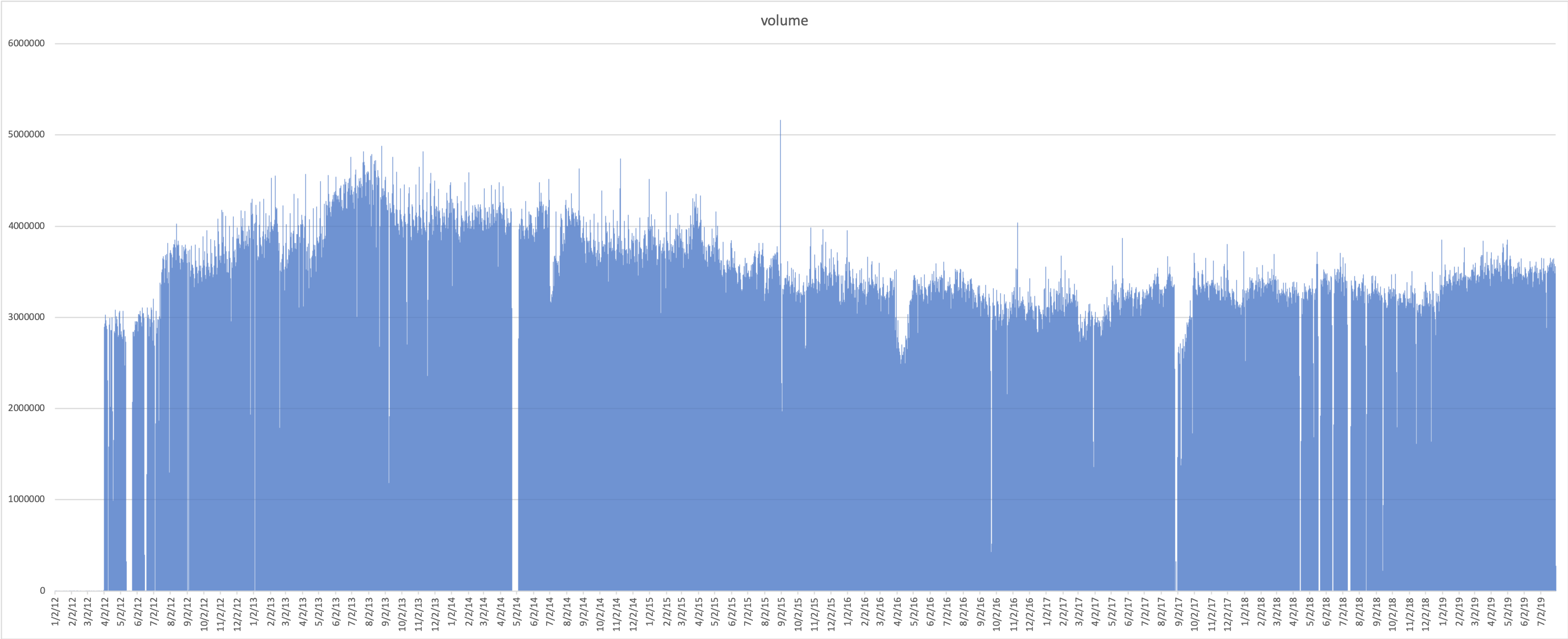


In partnership with The Annenberg School, we compiled a dataset of historical Tweets, which is now part of the iWRDS Data Catalog. Collection began in April 2012 and ended in November 2022. The total dataset represents about 1% of the total Twitter volume. Access to the historical dataset can be requested here (PennKey required). The database uses Amazon Web Services’s Athena offering and is queryable using SQL. Queries can be made using the AWS console or using an ODBC connection on the HPCC. See “Using Amazon Athena To Access Data” for detailed information about how to access Wharton-maintained datasets through Amazon Athena once you have been granted access.
Sample Queries
To search for the phrase `wharton school` (case insensitive) within the `extended_full_text` of all tweets between 09/02/2013 and 09/14/2013:
SELECT extended_full_text
FROM "whartweet"."tweets"
WHERE lower(extended_full_text) LIKE '%wharton school%'
AND CONCAT(year, month, day)
BETWEEN '20130902'
AND '20130914'
returns:
extended_full_text 1 Wharton school of business at upenn women in business convention? Sign me up! #phillylife
To search for tweets by a list of `user_screen_name` you could do something like:
SELECT user_screen_name,extended_full_text
FROM "whartweet"."tweets"
WHERE user_screen_name in ('UPenn_MedEthics', 'LibrarianUPenn', 'FOCUS_UPenn', 'UPennGCB', 'Upenn_REES', 'CPHIatUPenn')
AND CONCAT(year, month, day)
BETWEEN '20180101'
AND '20191019'
To retrieve the most recent Tweet in English in the database (as of July 29th, 2019):
SELECT created_at,
extended_full_text,
id,
timestamp_ms
FROM "whartweet"."tweets"
WHERE year = cast(YEAR(current_date) AS VARCHAR)
AND month = lpad(cast(month(now()) AS VARCHAR), 2, '0')
AND day = lpad(cast(day(now()) AS VARCHAR), 2, '0')
AND hour = lpad(cast(hour(now()) AS VARCHAR), 2, '0')
AND lang = 'en'
ORDER BY timestamp_ms DESC limit 1
You can learn more about lpad, dates and formatting here.
created_at extended_full_text id timestamp_ms 1 Mon Jul 29 19:24:24 +0000 2019 @amerix @RobertAlai Nice info,researchers say you're to cut 100% tobacco from your intake, the others you should regulate since it's the amount of carcinogens taken in the body that slowly corrode the mucosal linings of surfaces such as throat, stomach,colon causing #Cancer to develop #JoyceLaboso 1155922038655242240 1564428264665
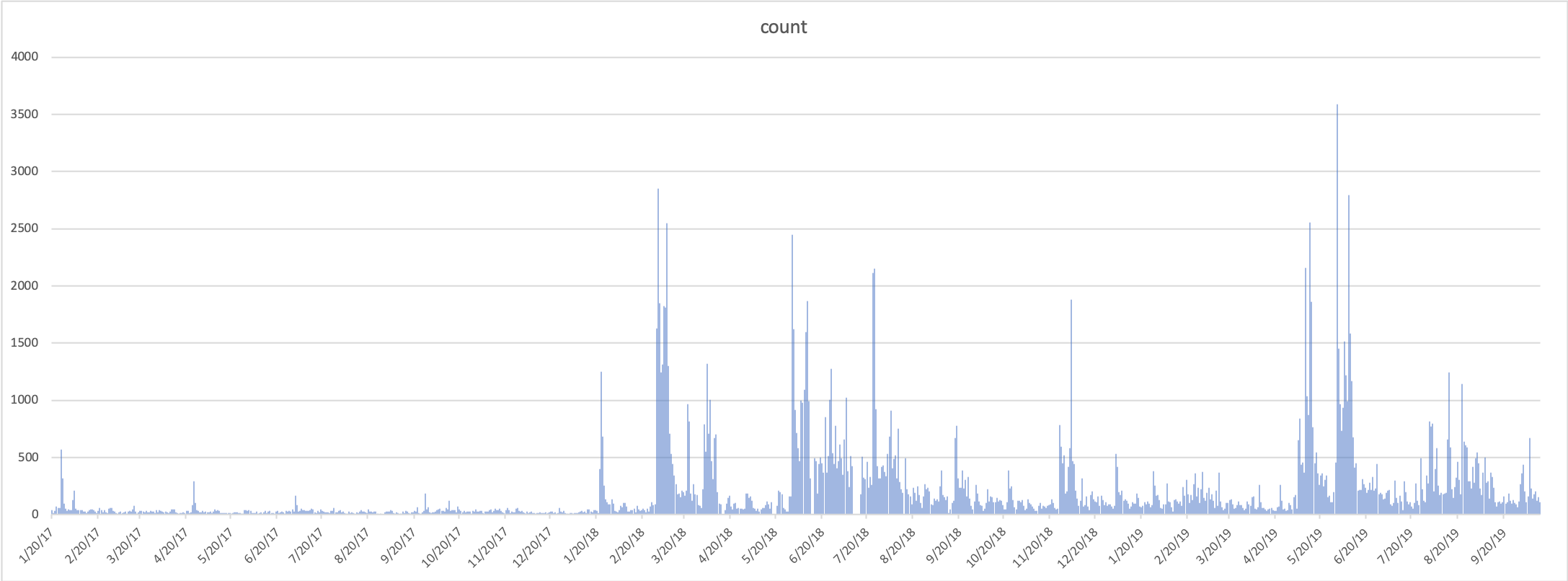
To chart the use of the term `tariff` since 1/20/2016, you could write a query like:
SELECT year,
month,
day,
CONCAT(month, '/', day, '/', year) AS date,
count(*) count
FROM "whartweet"."tweets"
WHERE lower(extended_full_text) LIKE '%tariff%'
AND CONCAT(year, month, day) >= '20170120'
GROUP BY year, month, day
ORDER BY year, month, day
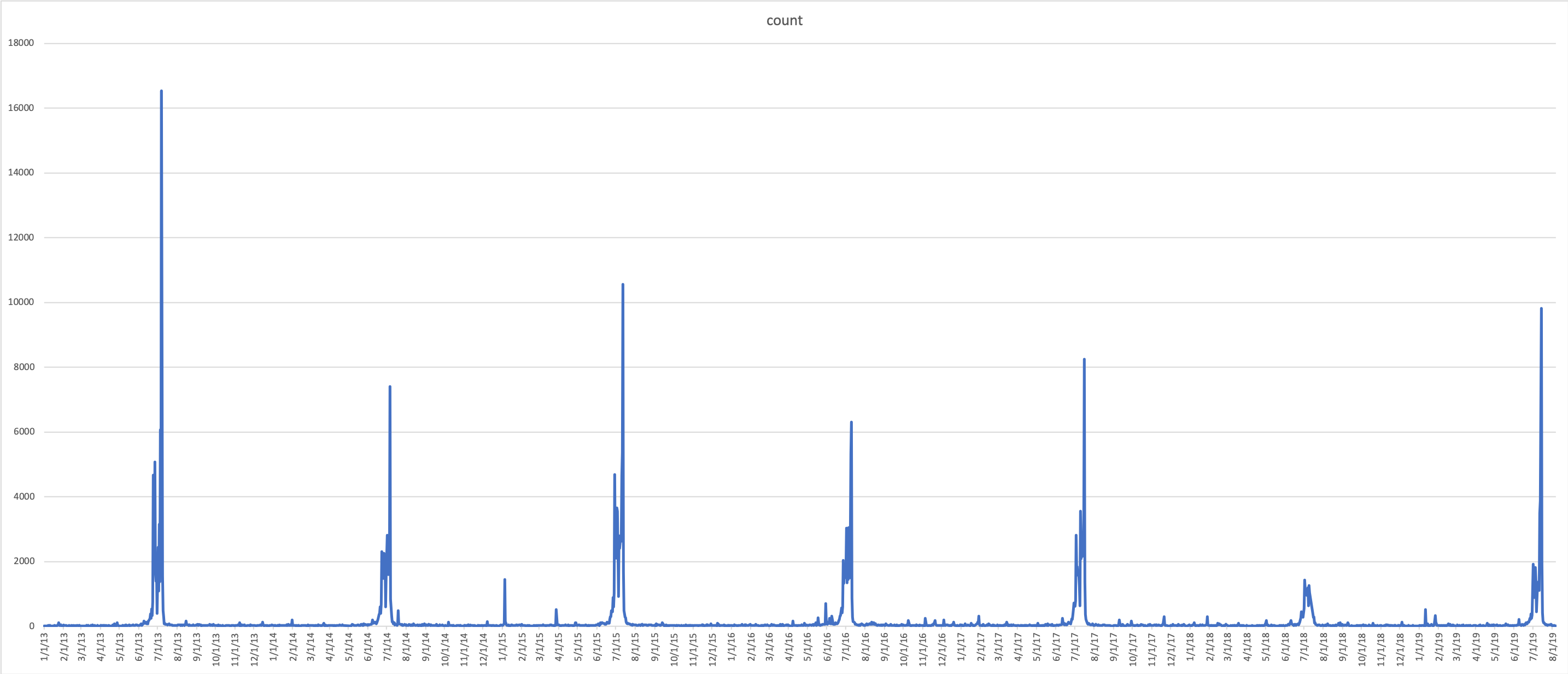
SELECT year,
month,
day,
CONCAT(month, '/', day, '/', year) AS date,
count(*) AS count
FROM "whartweet"."tweets"
WHERE lower(extended_full_text) LIKE '%wimbledon%'
AND CONCAT(year, '-', month, '-', day) >= '2013-01-01'
GROUP BY year,month,day
ORDER BY year, month, day
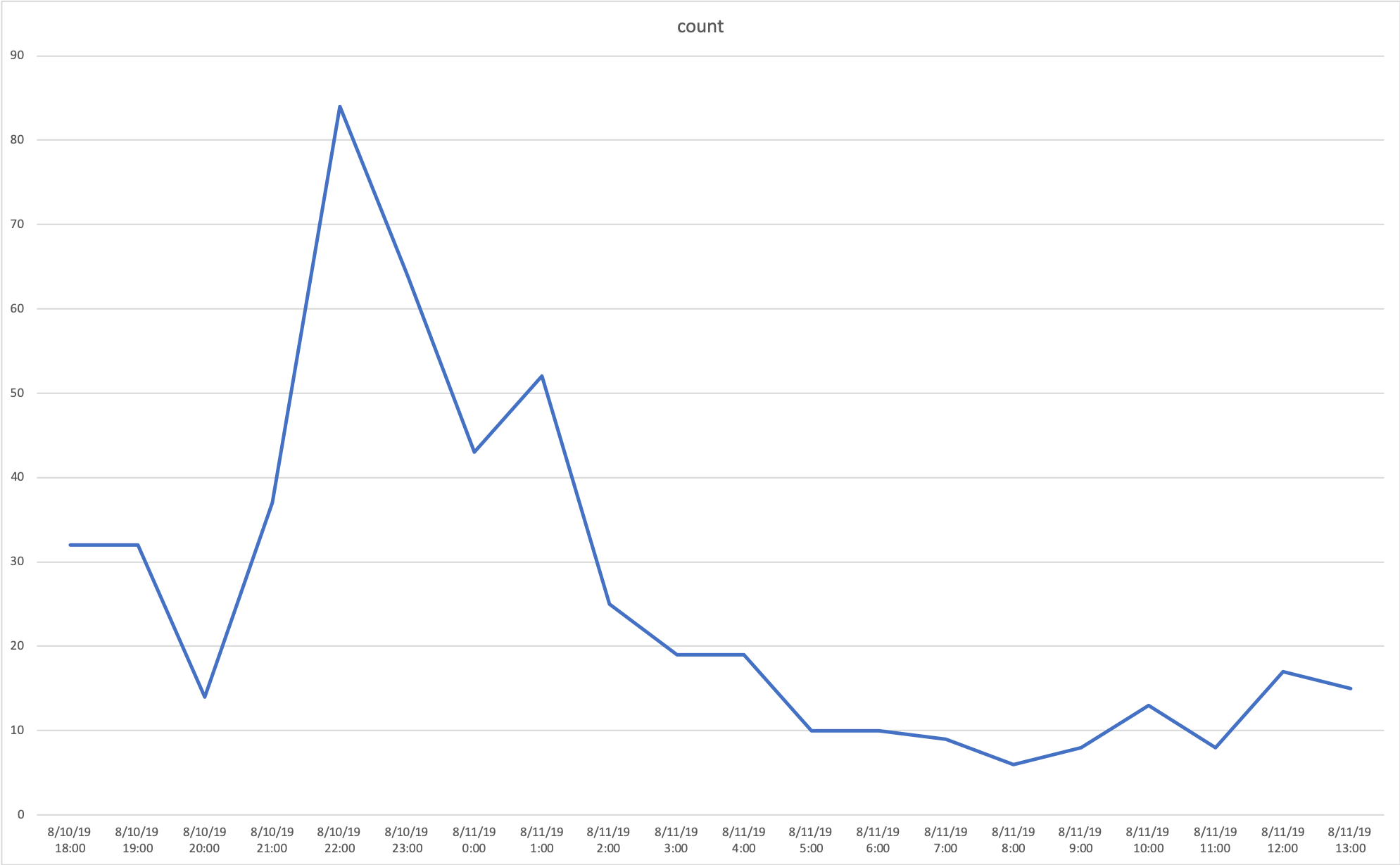
You can select tweets between two date/times like:
SELECT year,
month,
day,
hour,
CONCAT(month, '/', day, '/', year, ' ' , hour, ':00') AS date,
count(*) AS count
FROM "whartweet"."tweets"
WHERE rt_id = 1160256105399967744
AND CONCAT(year, month, day, hour)
BETWEEN '2019081016'
AND '2019081113'
GROUP BY year, month, day, hour
ORDER BY year, month, day, hour
Ordering Dates
Currently the `created_at` field is a string, so date ordering must be done on the `timestamp_ms` field. You can limit your search space using the following WHERE statement:
WHERE CONCAT(year, '-', month, '-', day) >= '2016-01-20'
You can convert a Unix Epoch timestamp to a human readable format and visa versa here.
Schema
All data is collected at tweet created_at time, and not all fields are available for all years. Fewer fields are available for tweets created before April 23, 2019.
- created_at (string): A datetime string of the tweets posting formatted like `Mon Jul 15 17:08:32 +0000 2019`
- timestamp_ms (string): A string representation of a bigint of the number of seconds since the Unix Epoch
- id (bigint): A integer representation of the Tweet ID
- id_str (string): A string representation of the Tweet ID
- extended_full_text (string): The body of the full tweet text (280 characters)
- user_id (string): A string representation of the Tweet’s user ID
- user_name (string): A string representation of the Tweet’s user name
- user_screen_name (string): A string representation of the Tweet’s user screen name
- user_followers_count (int): An integer representation of the Tweet’s user followers count
- user_location (string): A string representation of the Tweet’s user set location
- user_created_at (string): A datetime string representation of the Tweet’s user account creation formatted like `Mon Jul 15 17:08:32 +0000 2019`
- user_friends_count (int): An integer representation of the Tweet’s user friends count
- user_statuses_count (int): An integer representation of the Tweet’s user total statuses
- user_verified (boolean): Set to true if the Tweet’s user account has been verified
- source (string): A string representation of the utility used to post the Tweet. (e.g. `<a href=”http://twitter.com/download/android” rel=”nofollow”>Twitter for Android</a>`)
- truncated (boolean): Indicates whether the value of the
textparameter was truncated - in_reply_to_status_id (bigint): If the represented Tweet is a reply, this field will contain the integer representation of the original Tweet’s ID
- in_reply_to_status_id_str (string): If the represented Tweet is a reply, this field will contain the string representation of the original Tweet’s ID
- in_reply_to_user_id_str (string): If the represented Tweet is a reply, this field will contain the string representation of the original Tweet’s user ID
- in_reply_to_screen_name (string): If the represented Tweet is a reply, this field will contain the screen name of the original Tweet’s author
- is_quote_status (boolean): Indicates whether this is a Quoted Tweet
- lang (string): Tweet’s language using bcp47
- possibly_sensitive (boolean): This field only surfaces when a Tweet contains a link. The meaning of the field doesn’t pertain to the Tweet content itself, but instead it is an indicator that the URL contained in the Tweet may contain content or media identified as sensitive content.
- withheld_copyright (boolean):When present and set to “true”, it indicates that this piece of content has been withheld due to a DMCA complaint
- place_name (string): Short human-readable representation of the place’s name
- text (string): The possibly truncated text of the tweet. Best to use extended_full_text
- long (float): The longitude of the Tweet’s location
- lat (float): The latitude of the Tweet’s location
- quoted_status_id_str (string): This field only surfaces when the Tweet is a quote Tweet. This is the string representation Tweet ID of the quoted Tweet
- place_country_code (string): Shortened country code representing the country containing this place
- rt_* Any column prefixed with `rt_` will contain information of the parent Tweet. Only present for Retweets.
- year (string): A partition field for the Tweet’s
created_atyear. - month (string): A partition field for the Tweet’s
created_atmonth. - day (string): A partition field for the Tweet’s
created_atday. - hour (string): A partition field for the Tweet’s
created_athour.