Working with Jehoshua Eliashberg and Jeremy Fan within the Marketing Department I have developed a reusable Naive Bayes classifier that can handle multiple features. This is a useful algorithm to calculate the probability that each of a set of documents or texts belongs to a set of categories using the Bayesian method.
The package assumes a word likelihood file likelihoods.csv has been previously calculated and is formatted like:
| Word | Animal | Human | Plant |
| cat | 0.33 | 0.03 | 0.05 |
| dog | 0.33 | 0.02 | 0.05 |
| leaves | 0.05 | 0.03 | 0.4 |
| tree | 0.05 | 0.02 | 0.4 |
| man | 0.12 | 0.45 | 0.05 |
| woman | 0.12 | 0.45 | 0.05 |
The likelihoods for each feature must sum to 1.0 and you can have as many features as you wish. It is required to have a header titled Word referencing the feature followed by the assigned probabilities to all your desired features.
I asked Jeremy how he calculated his likelihood table for a project working with customer generated reviews of bicycles and he replied:
“I created the likelihood table by first creating the lexicon. I basically took this article on how to pick a bike and generated the lexicon for each category we were measuring. Then, I applied Laplace Smoothing to make sure each word in my lexicon appeared at least once in each category. The likelihood of a given word in a given category was calculated by the frequency of this word within the category divided by the sum of the frequencies of all words within the category.”
So let’s assume you have an unlabeled input CSV file input.csv formatted like:
| ID | Text |
| 1 | The cat is my pet and he is lovely. A dog will not do. |
| 2 | The man and woman had a cat and lived under a tree |
| 3 | The tree had lots of leaves |
| 4 | A man lives under a tree with many leaves. A woman has a cat as a pet |
| 5 | The dog and cat chased the man under the tree |
| 6 | The man and woman live in a house. |
It is required that the document header have a item titled Text referring to the document you want to classify. All other fields will be ignored but will be included unmodified in the classifier’s output file.
You can run this program on the HPCC using the following commands (in this example we will use an interactive logon qlogin):
From the HPCC login node, log in to an interactive session
$ qlogin
enable python 3
$ source /opt/rh/rh-python34/enable
Set up your virtual environment
$ mkvirtualenv <whatever you want to call your virtualenv>
Install the Multi-function Naive Bayes Classifier package
$ pip install mfnbc
Launch an interactive python shell
$ python
>>> from mfnbc import MFNBC
>>> m = MFNBC('likelihoods.csv', 'input.csv', True, 'out_filename.csv')
>>> m.write_csv()
>>> exit()
You should see a new file titled out_filename.csv with the following data:
| ID | reviewText | Animal | Human | Plant |
| 1 | The cat is my pet and he is lovely. A dog will not do. | 0.972321429 | 0.005357143 | 0.022321429 |
| 2 | The man and woman had a cat and lived under a tree | 0.580787094 | 0.2969934 | 0.122219506 |
| 3 | The tree had lots of leaves | 0.01532802 | 0.003678725 | 0.980993256 |
| 4 | A man lives under a tree with many leaves. A woman has a cat as a pet | 0.334412386 | 0.1026038 | 0.562983814 |
| 5 | The dog and cat chased the man under the tree | 0.921839729 | 0.00761851 | 0.070541761 |
| 6 | The man and woman live in a house. | 0.065633546 | 0.922971741 | 0.011394713 |
About The Maths
This package relies on simple arithmetic to compute the final posterior probabilities for a set of features over a set of texts within a corpus.
So for each text in the corpus, the package looks to see if the word is contained in the provided likelihood table. If it is found, the posterior probabilities for each feature are updated using Bayesian statistics.
![]()
where ![]() is:
is:
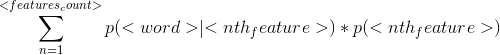
You can read more about the Mfnbc package here https://github.com/wharton/mfnbc